[yolov3学习记录2]yolov3官网样例训练与识别
yolov3官网 YOLO: Real-Time Object Detection (pjreddie.com)
在学习如何使用训练集训练时,首先是在网上参考许多前辈的博客,但发现其中的大部分都是用xml文件训练的,而目前手头上只有txt的训练标签。所以,一开始是寻找这两者的关系。
找到xml怎么来的。看了许多博客后,xml标签从图片标记得出,而图片标记则用到labelling这个软件,网上安装这个软件类似于安装python的库还有jupyter notebook差不多,要用到pip install,但毕竟我是在Windows平台,找找还真找到了exe的已编译版本。
Labelling的基本操作。导入文件夹,点create/nrec box来划框框,并设置好标签名称。然后保存再按d到下一张,直到把所有的图片都标记。此时,设置的保存地址文件夹便会有这些xml标签。
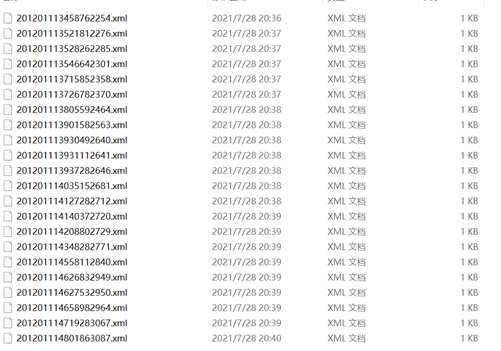
Xml文件内容。如下图,和html还有js这些东西比较类似,以前在学习api的时候学习过,我理解为一个集合里面再包含一个集合,通过拆分集合可以获得储存内容,也可以通过一个个嵌套获得这么一个xml文件。
Size:width height自然是图片长宽,depth是图片深读,3应该表示这是一个rgb的彩图。
Object:name 标签名
Bndbox:标签对应框选的坐标
其他元素好像不重要,可以乱填。

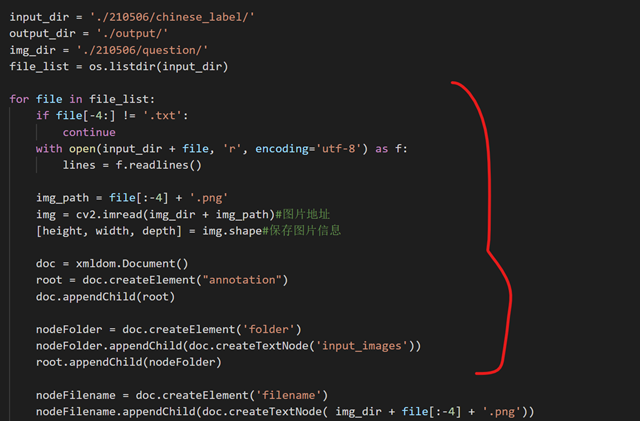
师兄发的转换格式py源码。如下图,正如上一段说的,是把一层层嵌套得来的。只需要修改上面的3行dir文件夹位置即可自动转换(img_dir是我自己加的)。
使用yolo官网的VOC例子。

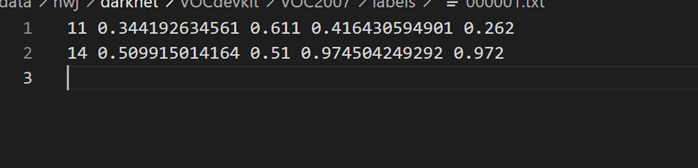
打开新转换的txt标签发现,和之前接触的十分不一样。
继续看yolo官网代码。

上半段是将这几个train和val的数据列表合成为train的,用于训练,下半段是改训练集位置。
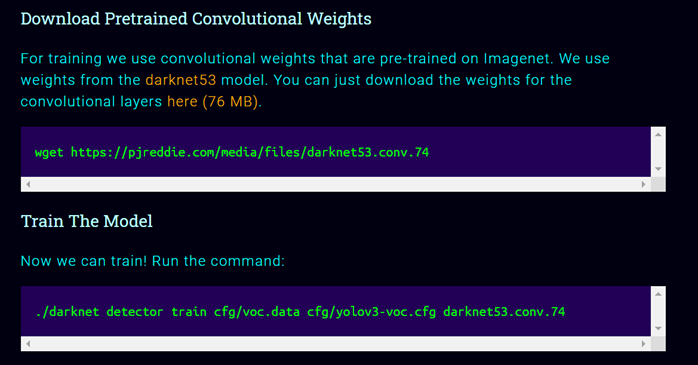
下载个预权重然后开始训练。这时,训练时如下。
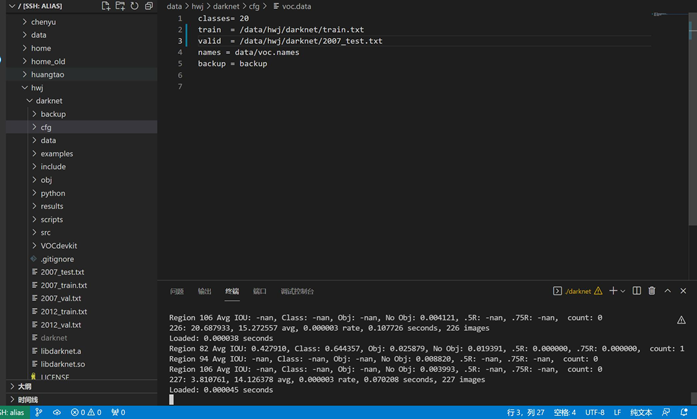
可是跑完后,识别却啥都识别不出。
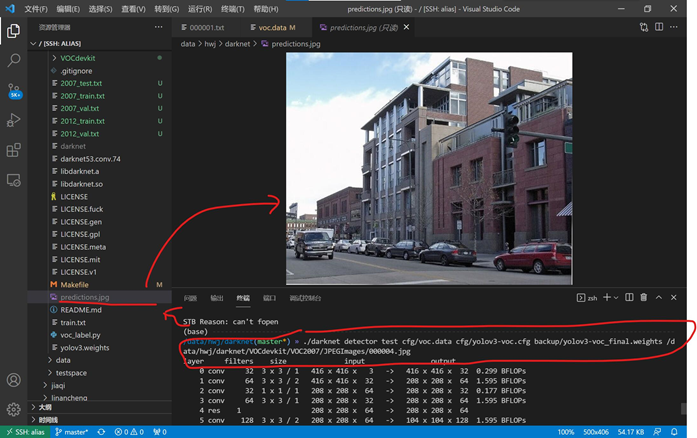
由于是一步步按照yolo官网来的,没想到官网也有错。看了好多大神的操作才发现这里。
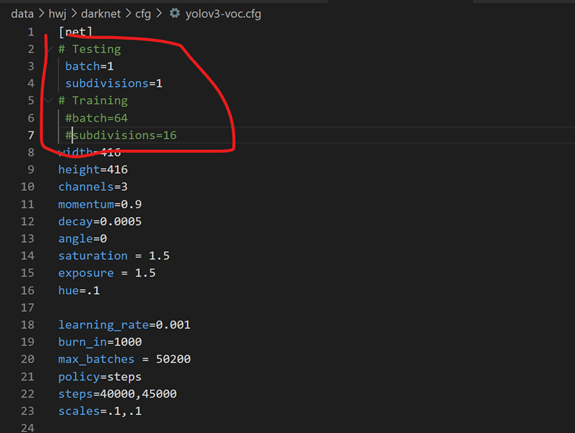
在cfg/yolov3-voc.cfg里面,若是进行训练,就要把testing的两行注释,把training的两行不注释,测试时则是反过来。如下:
最后,通过将近24h的训练,终于搞定了。不过有点抽筋。

其实经过440w次迭代,我觉得理论上已经非常准确了,识别成这样,我觉得是标签出问题,要不怎么所有人都是bird。
中途还有好多小插曲的,忘了,嘻嘻。