[阅读笔记]TSNs: Towards Good Practices for Deep Action Recognition
文章发表于2016 ECCV,主要探讨了深度行为识别领域中的最佳实践。文章指出,现有基于CNN的分类方法在长期时间结构的捕获上不如手工设计的特征,并因视频数据集量不足可能导致过拟合。作为解决方案,文章提出了一个高效模型,专注于长期时间结构的捕获,并讨论了在数据有限的情况下如何有效训练模型,包括跨模态预训练、规范化技术和数据增强,同时还介绍了第一个端到端的视频时序建模模型。
1 Introduction
在分类中,现有的CNN based性能还比不过手工设计feature的方法,作者认为主要归结于2方面的原因:
- Long-Range temporal structure很重要,但是现在的主要还在关注Short-Term motions和Appearance。
- 现有的视频数据集量不够,可能会过拟合。
2 Contributions
- 提出一个高效的,long-range temporal structure 捕获能力的模型。
- 怎么在有限的数据下有效地训练模型(Cross Modality Pre-training、Regularization Techniques、Data Augmentation)。
- 第一个end-to-end的video时序建模模型。
3 Method
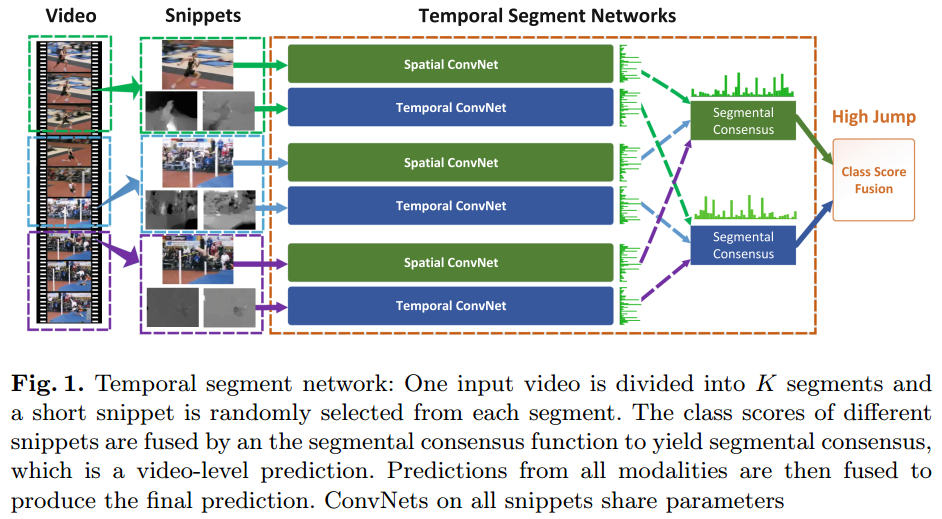
- 将video均匀地分割成K哥Segment
- 每个segment里面随机抽取一帧RGB图片和 a stack of consecutive optical flow(实验中设置为连续的5帧)。
- 经过BN-Inception进行特征提取。
- RGB、Optical两个Stream各自对probabilities进行avg然后softmax。
- 融合后的probabilities再进行avg。
4 少数据有效训练模型,减缓过拟合的方法
4.1 Cross Modality Pre-training
在ImageNet上训练的参数,经过将RGB 3 channels的参数avg后,复制成Optical Flow需要的channels来使用。
4.2 Regularization Techniques
作者提到,普通的BN Layer,对数据进行Norm有利于加快训练,但是,这个模态的特征分布学习好怎么Norm后,迁移到另外一个模态里面的话,特征的分布改变了,原来Norm的参数将不再能帮助新模态数据有效Norm成原来的分布。
改进:预训练好后,将第一层BN Layer之外的BN Layers全部冻住,第一层的BN Layer可以在新模态中进行微调。
4.3 Data Augmentation
提出2个新模态:
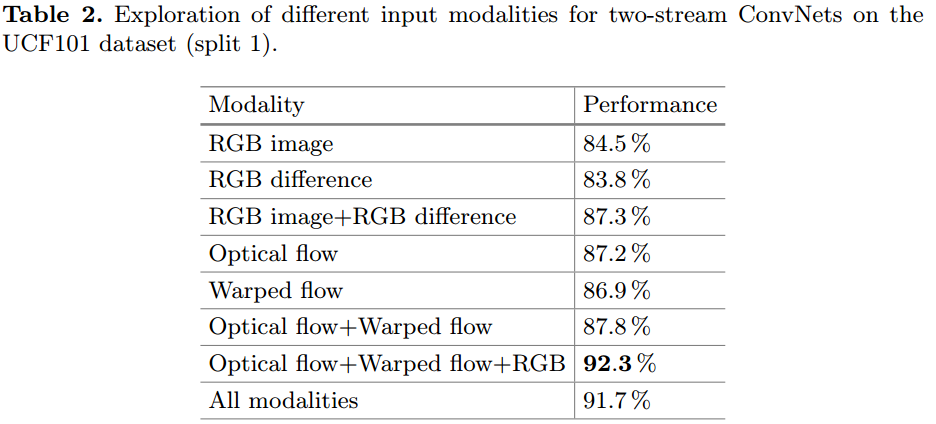
- RGB Difference,计算前后两帧RGB image的差距。有用,但不稳定,可以作为没Optical Flow时候的补充,计算快,单独不如RGB。
- Warped flow,计算光流的整体动向之后,整个光流减去整体动向的平均值,减少是视角移动带来的影响。有用,单独不如Optical Flow。

5 Experiments
5.1 消融

5.2 可视化
以下是作者进行模型可视化的具体步骤:
选择白噪声图像作为起点:DeepDraw 工具从一个只包含白噪声的图像开始,这意味着初始图像是随机的,不包含任何特定的结构或模式。
迭代梯度上升:使用梯度上升方法来调整图像中的像素值。这个过程是通过计算网络对于某一类别(例如某个特定动作)的响应并根据这个响应的梯度来更新图像来实现的。具体来说,就是修改图像以增加网络对于特定类别的输出得分。
重复迭代直至收敛:这个过程在多次迭代中重复,每次迭代都根据网络的反馈来更新图像。随着迭代的进行,图像逐渐演变为更能激活网络特定部分的形式。
生成特定类别的可视化:最终,经过多次迭代后,得到的图像可以被认为是对网络中所学习特征的一种可视化。这些图像通常会突出那些对于网络识别特定类别最重要的视觉模式。
适配光流模型:原始的 DeepDraw 工具是为处理RGB数据设计的。为了可视化基于光流的模型,作者对工具进行了调整,使其能够与他们的时间流卷积网络一起工作。
通过这种方法,作者能够可视化不同配置下(例如,有无预训练,使用不同输入模态等)的空间流(基于RGB)和时间流(基于光流)卷积网络的学习特征。这些可视化结果有助于更好地理解网络是如何响应不同类型的动作,并揭示了网络如何在长期时间结构建模方面取得进展。
