深度学习模型轻量化方法总结
注:本文章由scutvk纯原创,截自本人报告《模型轻量化与软硬件实现 初步调研报告》,禁止私自转发。
深度学习模型轻量化方法旨在通过减少模型参数、降低计算复杂度和减小存储需求等手段,在保持较高性能的同时实现模型的轻量化。这些方法可以分为几类,包括剪枝、低秩分解、量化、知识蒸馏、紧凑网络架构、稀疏性和其他一些相关方法。它们之间的关系和差异主要体现在降低模型复杂度的策略、压缩程度和性能损失等方面。剪枝方法通过移除不重要的神经元或连接来减少模型参数;低秩分解则利用矩阵分解来降低模型参数数量;量化方法将权重和激活值用较少的比特数表示以减小存储和计算需求;知识蒸馏将一个大型教师模型的知识迁移到一个较小的学生模型;紧凑网络架构通过设计更高效的网络结构来降低模型复杂度;稀疏性方法则尝试在模型中引入稀疏性,以减少参数数量和计算量。此外,还有一些其他的轻量化方法,如神经结构搜索(NAS)、提前退出(early exiting),它们在不同程度上结合了上述方法的优点。在接下来的部分,将详细介绍这些轻量化方法的原理、优缺点和应用场景。
2.1 剪枝
剪枝是一种常见的深度学习模型轻量化方法,旨在通过移除不重要的神经元或连接来减少模型参数,降低计算复杂度和存储需求。剪枝方法主要分为结构化剪枝和非结构化剪枝。
结构化剪枝通过移除整个神经元或卷积核来降低模型复杂度,从而保留了模型的稀疏结构,便于硬件加速。常见的结构化剪枝方法包括卷积核剪枝、通道剪枝等。非结构化剪枝则通过移除单个权重来压缩模型,这种方法可以获得更高的压缩率,但可能导致不规则的稀疏性,难以直接利用硬件加速。
2.1.1 结构化剪枝
结构化剪枝是一种基于层或通道的剪枝方法。在这种方法中,我们裁剪整个神经元、通道或层,而不仅仅是单个的权重。结构化剪枝的主要优点是,剪枝后的模型具有良好的硬件友好性,因为剪枝后的网络结构仍然是规整的。但是,与非结构化剪枝相比,结构化剪枝可能更难找到最优的剪枝策略,因为剪枝粒度较粗。
1. 通道剪枝
通道剪枝(channel pruning),主要应用于CNN。通道剪枝的目标是通过删除整个通道来减少网络中的参数数量,从而降低计算和存储需求,同时尽量保持网络的性能。
在卷积神经网络中,一个卷积层通常包含多个卷积核,每个卷积核都负责提取输入数据的特定特征。这些卷积核在卷积操作后会产生多个通道的输出。通道剪枝方法的核心思想是识别并剪除那些对最终输出影响较小的通道,从而简化网络结构。
2. 层剪枝
层剪枝(Layer Pruning),涉及到删除整个网络层(例如卷积层或全连接层),以简化网络结构。这种方法通常需要仔细分析各层对模型性能的贡献,以确定可以安全剪除哪些层。层剪枝可能需要较多的实验和调整,以找到在保持模型性能的同时实现良好压缩效果的剪枝策略。
3. 分组卷积剪枝
分组卷积剪枝(Grouped Convolution Pruning),将卷积层的输入和输出通道分成多个组,每个组内的通道之间只进行卷积操作。这样可以减少参数数量和计算复杂度。通过调整组的数量,可以在减少计算量和保持性能之间找到平衡。

2.1.2 非结构化剪枝
非结构化剪枝是一种基于权重重要性的剪枝方法。在这种方法中,我们根据权重的大小来裁剪神经网络中的连接。较小的权重被认为是不重要的,因此被剪掉。这样可以减少网络中的参数数量,从而降低计算和存储需求。非结构化剪枝的主要优点是灵活性,因为可以在任何层和任何神经元之间进行剪枝。但它的一个缺点是,剪枝后的模型可能不具备良好的硬件友好性,因为剪枝后的稀疏连接可能导致不规则的内存访问和计算。
在非结构化剪枝中,我们会考虑整个网络中的所有权重,而不是单独针对每个层进行剪枝。非结构化剪枝的一个常见策略是设置一个阈值,然后剪掉所有绝对值小于这个阈值的权重。这种方法可以在整个网络范围内产生稀疏连接,从而减少模型的参数数量和计算需求。
2.1.3 条带剪枝
条带剪枝(stripe pruning),它介于结构化剪枝和非结构化剪枝之间。在条带剪枝中,我们剪掉神经网络中连续的一组权重,形成一个“条带”。这种剪枝方法试图在保持一定程度的规整性(以实现较好的硬件友好性)和灵活性(以实现更精确的剪枝策略)之间取得平衡。
例如,在一个卷积层中,可以沿着宽度、高度或通道方向剪掉一整条权重。这样做可以减少参数数量,同时保持一定程度的规整性,从而在不显著降低性能的情况下降低计算和存储需求。
相比于传统的滤波器级别剪枝方法,条带剪枝方法可以更细粒度地控制剪枝程度,并且可以减少对模型性能的影响,同时还可以提高剪枝后模型的稀疏性。
然而,条带剪枝相对于结构化剪枝和非结构化剪枝来说,可能在实际应用中较少被使用。结构化剪枝和非结构化剪枝已经在许多场景中取得了良好的性能和压缩效果。在某些情况下,可以尝试将条带剪枝与其他剪枝方法结合使用,以进一步优化神经网络。
2.2 低秩分解
传统的低秩分解是指将一个矩阵分解为两个低秩矩阵的乘积,其中这两个低秩矩阵的秩远远小于原始矩阵的秩。这种分解可以在一定程度上压缩数据,降低存储和计算复杂度。
这种方法将一个大型的矩阵或者张量分解成多个小型的低秩矩阵的乘积,从而可以降低数据的复杂性和存储空间需求。具体来说,假设有一个数据矩阵X,我们可以通过分解成两个小型的矩阵U和V的乘积,即X=UV,来表示X。其中U为m*k的矩阵,V为k*n的矩阵,k通常比m和n要小很多。由于U和V的秩都比X的秩要低,因此可以用更少的空间存储它们,并且使用它们进行计算的速度也更快。另外,矩阵分解也可以用于特征提取、数据降维等任务中。
2.3 量化
量化技术是指将连续的数值或信号转换为离散的数值或信号的过程。在机器学习和深度学习领域中,量化通常用于减少神经网络中参数的位数和精度,以降低模型的存储和计算开销。通过将参数量化为较低位数的整数或浮点数,可以大幅减小模型的大小并提高模型在移动设备等资源有限的环境下的性能。同时,量化技术也可以用于降低神经网络计算过程中的功耗和延迟,从而提高模型的运行速度。量化技术是深度学习中的一个重要技术,在很多实际应用中具有很高的实用价值。
在神经网络中,量化指的是将模型中的浮点数参数转换为更小的整数或固定位宽的数字,以便于存储和计算。这通常可以通过减少模型中参数的位数来实现,从而降低内存和计算开销,并提高推理速度。量化技术可能会对模型的精度造成一定的影响,因为它减少了参数的精度。
在实际应用中,模型的参数通常是FP32单精度,我们可以使用整数、FP16、TF32、MPT等代替。
2.3.1 INT
PyTorch中的Quantized Tensor可以存储 int8/uint8等类型的数据。
数据类型:
- weight的8 bit量化 :data_type = qint8,数据范围为[-128, 127]
- activation的8 bit量化:data_type = quint8,数据范围为[0, 255]
同时,也有许多专用于整数精度计算的硬件:

不过,在训练的前期,通常不使用INT8/UINT8精度,因为这可能会损害模型的质量和表现。但是,在训练过程中,当模型达到一定的准确度和稳定性时,可以考虑通过量化技术将FP32权重压缩为INT8/UINT8格式,使用低精度的整数运算来加速模型的推断和部署。
2.3.2 FP16
半精度浮点(FP16)训练:这种方法通过将权重和激活值从32位浮点数(FP32)降低到16位浮点数(FP16)来减少存储和计算需求。半精度浮点训练可以在支持FP16计算的硬件上提高训练速度,并降低内存消耗。
NVIDIA 20系Turing架构之前,GPU的单精度、半精度计算速度一样,单Turing架构及之后,半精度计算速度一般都是单精度计算的数倍:

使用FP16相对于FP32可能带来以下影响:
- 减少显存占用:由于FP16数据类型的尺寸比FP32小一半,因此使用FP16可以减少模型和梯度张量的显存占用。这可以使得更大的模型能够在相同的设备上进行训练,并且可以提高GPU并行计算的效率。
- 加速训练:由于FP16的计算速度更快,因此使用FP16可以加速模型的训练。这是因为在训练过程中,大量的计算都是矩阵乘法运算,而GPU对FP16的矩阵乘法运算支持得更好,可以实现更高的并行度,从而提高训练速度。
- 可能导致数值不稳定:FP16对于非常小或非常大的数值,精度可能会受到影响,从而导致数值不稳定的问题。这可能会对优化器的性能产生负面影响,并且在训练过程中可能会出现NaN或Inf等异常情况。
- 可能降低模型的精度:由于FP16的精度较低,当模型的参数或梯度具有较大的范围时,使用FP16可能会导致精度损失,并且可能会降低模型的准确性。
2.3.3 TF32
Tensor Float 32(TF32)是一种新的浮点数格式,由NVIDIA在其最新的Ampere架构中引入。TF32 是一种截短的 Float32 数据格式,将 FP32 中 23 个尾数位截短为 10 bits,而指数位仍为 8 bits,总长度为 19 (=1 + 8 + 10) bits。
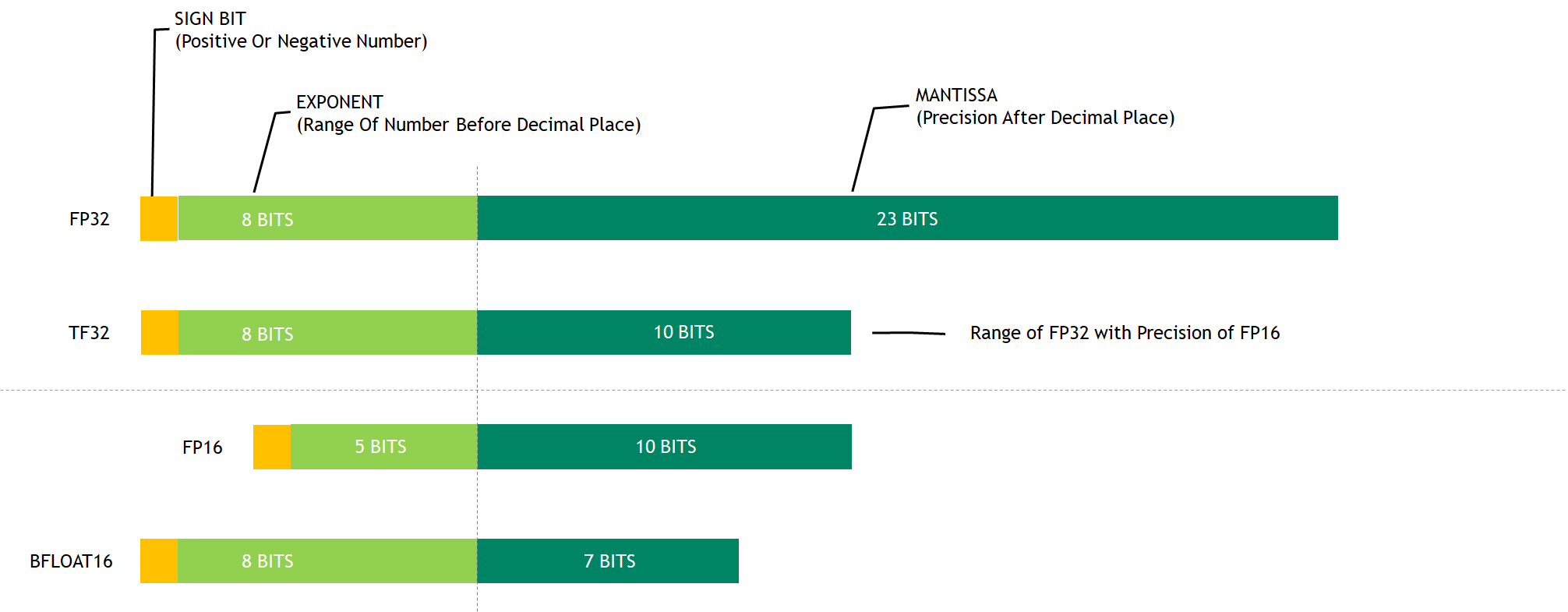
TF32 可以实现与 FP16 相同的计算速度,同时对计算结果的影响与 FP32 几乎没有变化。
2.3.4 MPT
在实际应用中,经常面临FP32计算速度过慢,而FP16又可能因为精度不足带来数据溢出问题和舍入误差等问题。混合精度训练MPT(Mixed Precision Training)是一种神经网络训练方法,利用半精度浮点数(16位)加速模型训练过程。在混合精度训练中,网络权重和梯度使用半精度浮点数来计算,而所有的累积操作和参数更新则使用单精度浮点数(32位)进行计算。
2.4 知识蒸馏
知识蒸馏是一种深度学习模型轻量化方法,旨在通过将一个大型教师模型的知识迁移到一个较小的学生模型,从而实现在保持较高性能的同时减小模型大小和计算复杂度。知识蒸馏的基本原理是让学生模型学习教师模型的输出分布,从而吸收教师模型的知识。
知识蒸馏的过程主要包括以下步骤:

2.5 紧凑网络架构
紧凑网络架构是一种深度学习模型轻量化方法,旨在通过设计更高效的网络结构来降低模型复杂度,从而实现在保持较高性能的同时减小模型大小和计算复杂度。紧凑网络架构的基本原理是利用更少的参数和计算量来实现同等甚至更高的性能。
在紧凑网络架构中,我首先想到在竞赛中最经常用到的CNN模型——EfficientNet。EfficientNet是一种基于神经网络的图像分类模型,由谷歌的研究团队在2019年提出。EfficientNet是通过在模型的宽度、深度和分辨率方面进行了一种称为Compound Scaling(复合缩放)的优化而设计出来的。
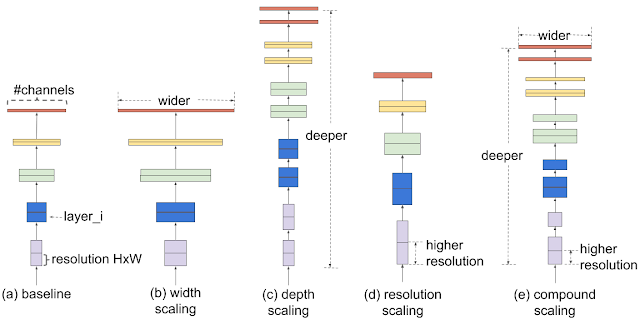
具体来说,Compound Scaling(复合缩放)包括以下三个方面:
- 网络深度:即网络层数,深度越大,网络的表示能力越强。通常,增加网络的深度可以帮助模型捕捉更多的抽象层次特征,从而提高性能。然而,过深的网络可能导致梯度消失或爆炸问题,以及过拟合现象。
- 网络宽度:即每层网络中的通道数或神经元数量。增加网络的宽度可以提高模型的容量,有助于学习更多的特征表示。但过宽的网络可能导致计算资源的浪费,以及训练和推理速度的降低。
- 输入分辨率:即输入图像的尺寸,分辨率越高,图像中的信息越丰富。通常,增加输入分辨率可以帮助模型捕捉更多的细节信息。然而,过高的分辨率会增加计算复杂度和内存消耗。
复合缩放通过在这三个维度上同时进行平衡的缩放,使得网络在保持较低计算复杂度和参数数量的同时,实现了高效的性能表现。在EfficientNet的设计过程中,研究者们通过系统地研究不同缩放比例对性能的影响,找到了一种最佳的复合缩放策略。这使得EfficientNet在各种图像分类任务中表现出色,同时具备较高的参数和计算效率。
2.6 稀疏性
稀疏性是指在模型中存在大量的零值或接近零值的参数,通过利用这些稀疏性,我们可以减少模型的参数数量,从而达到轻量化的目的。稀疏性可以从原始域或变换域中计算得出,进一步帮助我们识别并去除冗余或无关的参数。

2.6.1 原始域稀疏性
原始域稀疏性是指在模型参数的原始表示中存在稀疏性。例如,权重矩阵中可能存在大量的零值或接近零值的元素。通过识别并剔除这些无关紧要的参数,可以减少模型的存储和计算负担。原始域稀疏性的实现方法包括权重剪枝、正则化方法等。
为了利用原始域稀疏性,我们可以在训练期间将权重矩阵进行稀疏化。
- 首先,我们可以使用稀疏矩阵表示权重。这意味着我们只存储非零权重值,而不是存储整个权重矩阵。这可以大大减少模型的大小。
- 在训练过程中,我们可以引入L1正则化或者其他稀疏性惩罚项来鼓励模型学习稀疏的权重。通过对权重施加稀疏性约束,我们可以在训练期间逐步消除不重要的连接,从而减少模型的计算复杂性。
- 为了提高计算效率,我们可以使用专门针对稀疏矩阵操作的算法和库,例如SparseConvNet或Intel MKL等。
2.6.2 变换域稀疏性
变换域稀疏性是指将模型参数从原始域转换到另一个域,以便在该域中更容易地识别稀疏性。例如,可以将权重矩阵转换为频率域(如傅里叶变换或小波变换),在频率域中更容易发现稀疏性。然后可以通过阈值方法或其他技术去除不重要的参数,再将剩余参数转换回原始域。这样可以在不损失模型性能的情况下,实现模型参数的压缩。
离散傅里叶变换DFT
DFT (离散傅里叶变换) 公式:
X[k]=\sum_{n=0}^{N-1} x[n] \cdot e^{-j \frac{2 \pi n k}{N}}IDFT (逆离散傅里叶变换) 公式:
x[n]=\frac{1}{N} \sum_{k=0}^{N-1} X[k] \cdot e^{j \frac{2 \pi n k}{N}}优点:时域信息->频域信息
缺点:只能获取一段信号总体上包含哪些频率的成分,但是对各成分出现的时刻并无所知。因此时域相差很大的两个信号,可能频谱图一样。

短时傅里叶变换STFT
STFT为了在频域中表现出成分出现的时刻,在对原始信号进行DFT之前先进行固定时间间隔的时域分割。窄窗口时间分辨率高、频率分辨率低,宽窗口时间分辨率低、频率分辨率高。对于时变的非稳态信号,高频适合小窗口,低频适合大窗口。然而STFT的窗口是固定的,在一次STFT中宽度不会变化,所以STFT还是无法满足非稳态信号变化的频率的需求。



小波变换
相较于DFT用周期性的采样信号去采样,小波做的改变就在于,将无限长的三角函数基换成了有限长的会衰减的小波基。通过对小波进行平移来达到对不同时期的采样,对小波进行拉伸(改变频率)来对不同频率的信号采样。

小波变换公式:
W T(a, \tau)=\frac{1}{\sqrt{a}} \int_{-\infty}^{\infty} f(t) * \psi\left(\frac{t-\tau}{a}\right) d t离散余弦变换DCT
DCT(Discrete Cosine Transform,离散余弦变换)是一种将离散信号从时域转换到频域的方法,与DFT(Discrete Fourier Transform,离散傅里叶变换)类似。DCT的主要优势在于它的基函数是实数,因此在某些实际应用中,如图像和视频压缩,DCT通常具有更好的能量集中和更少的边界效应。
DCT和DFT之间的主要区别在于它们使用的基函数不同。DCT使用余弦函数作为基函数,而DFT使用复指数函数(包括正弦和余弦函数)作为基函数。
F(u, v)=\frac{1}{\sqrt{2 N}} C(u) C(v) \sum_{x=0}^{N-1} \sum_{y=0}^{N-1} f(x, y) \cos \left[\frac{(2 x+1) u \pi}{2 N}\right] \cos \left[\frac{(2 y+1) v \pi}{2 N}\right]C(u)=\left\{\begin{array}{ll} \frac{1}{\sqrt{2}}, & u=0 \\ 1, & u>0 \end{array}\right.参考:
2.7 其他的轻量化方法
2.7.1 神经结构搜索NAS
神经结构搜索(Neural Architecture Search,简称 NAS)是一种自动化技术,旨在搜索和优化神经网络的结构。传统上,神经网络的设计是一个复杂且耗时的过程,需要领域专家手动设计和调整网络结构。NAS 通过自动搜索过程简化了这个任务,使得机器学习系统能够自主找到最佳的网络结构以解决特定问题。
NAS 的工作原理是在一个预定义的搜索空间内进行探索,尝试不同的网络结构和超参数配置。搜索空间定义了可用的网络层、连接方式和其他潜在配置。然后,NAS 使用优化算法(如强化学习、进化算法、贝叶斯优化等)来探索这些可能的组合,并评估它们的性能。在搜索过程中,优化算法根据模型在训练数据上的表现来调整搜索方向,从而逐渐找到更好的网络结构。
经过足够长时间的搜索和评估,NAS 最终会找到一种网络结构,该结构在所给定的任务上具有较好的性能表现。这样的自动化方法可以节省大量的时间和资源,同时在某些情况下甚至可以找到超越人类专家设计的神经网络的解决方案。
然而,NAS 也有一定的局限性。其搜索过程可能需要大量的计算资源和时间,特别是在大型搜索空间中。此外,NAS 找到的网络结构可能难以解释和理解,这可能会影响到网络的可解释性和可维护性。尽管如此,NAS 仍然是一个非常有前景的研究领域,可以帮助推动神经网络设计的自动化和优化。
2.7.2 提前退出Early exiting
提前退出(Early exiting)是一种在深度学习模型,尤其是神经网络中使用的技巧。它的主要目的是在不损失过多性能的情况下,减少计算量和提高模型的计算效率。
在神经网络(尤其是深度神经网络)中,模型通常包括多层神经元。在传统的前向传播过程中,输入数据会经过所有层的计算,最后得到预测结果。然而,有时候模型在经过几层计算后,就已经可以得到足够好的预测结果。在这种情况下,继续进行更多层的计算可能会浪费计算资源。
为了解决这个问题,提前退出策略被引入到神经网络中。在这种策略下,网络的某些中间层会被设置为潜在的输出层。这意味着,当输入数据经过这些中间层时,可以根据某种标准(如置信度或损失函数阈值)来判断预测结果是否足够好。如果满足这个标准,模型可以提前终止计算,并输出当前层的预测结果。这样,模型可以在不影响输出质量的情况下,节省计算量和提高效率。
总的来说,提前退出(Early exiting)是一种在神经网络中提高计算效率的方法,它允许模型在满足一定条件时提前终止计算,并输出预测结果。